Tadalafil zeichnet sich durch eine außergewöhnlich lange Halbwertszeit im Vergleich zu anderen PDE5-Inhibitoren aus. Diese pharmakokinetische Eigenschaft führt zu einer verlängerten Exposition des Wirkstoffs im Organismus. Die Eliminationsrate hängt von der hepatischen Aktivität des CYP3A4-Enzyms ab. Lipophile Eigenschaften unterstützen eine weite Verteilung in unterschiedlichen Geweben. Eine ausgeprägte Stabilität gegenüber Nahrungsaufnahme macht den Stoff besonders konstant in seiner Wirkung. Unter generischen Präparaten wird cialis online häufig mit einem vergleichbaren pharmakologischen Profil beschrieben.
Complexity.ru
A Hybrid Neural Network and Virtual Reality System for Spatial Language Processing
Guillermina C. Martinez1, Angelo Cangelosi1, Kenny R. Coventry2
1School of Computing and 2Department of PsychologyDrake Circus, Plymouth PL4 8AA, UKguille@usitmail.com, acangelosi@plymouth.ac.uk, kcoventry@plymouth.ac.ukAbstract
shape) play an important role in the comprehension ofspatial prepositions. This paper describes a neural network model for the study
Traditionally, geometric constructs have been invoked to
of spatial language. It deals with both geometric and
underpin prepositions’ lexical entries (e.g., [10,11]). For
functional variables, which have been shown to play an
example, in the sentence, “The pear is in the bowl,” the
important role in the comprehension of spatial prepositions.
figure (the pear) is located in the region described by the
The network is integrated with a virtual reality interface for
prepositional phrase “in the bowl”, with the spatial relation
the direct manipulation of geometric and functional factors.
expressed by in corresponding to “contained interior to the
The training uses experimental stimuli and data. Results
Clearly, while geometry is important in the use and
generalization errors. Cluster analyses of hidden activationshow that stimuli primarily group according to extra-
geometric variables need to be invoked in order to account
for use and comprehension. For example the expression, theman is at the piano, implies that the man is playing thepiano, not just that he is in close proximity to it. There have
1 Introduction
been a number of empirical demonstrations showing thatextra-geometric factors play an important role in the use
The aim of this work is to develop a hybrid neural network
and comprehension of spatial prepositions. Functional
(NN) and virtual reality (VR) system for the study of spatial
language and cognition. It will also be tested as a prototype
underlying the meaning of the spatial prepositions in, on
natural language interface for virtual environments.
Functional relations have to do with how objects interact
understanding of spatial terms such as over, above, under,
with each other, and what the functions of objects are. For
and below, has proven to be an important experimental field
example, with in, Garrod and Sanford [7] and Coventry [3]
for the investigation of cognition [3,13]. The use of an
propose that the lexical entry is: in [functional containment
expression involving a spatial preposition in English
- in is appropriate if the ground is conceived of as fulfilling
conveys to a hearer where one object (figure) is located in
its containment function]. Whether or not in is appropriate
relation to a reference object (ground). Understanding the
depends on a number of factors which determine whether
meaning of spatial prepositions is of particular importance
the container is fulfilling its function. Empirical evidence
in semantics as they are among the set of closed class terms
for the importance of this functional analysis has been
which are generally regarded as having the role of acting as
forthcoming for topological prepositions.
organizing structure for further conceptual material [14].
It has also recently been shown that prepositions are
Recently, both experimental research and computational
influenced differentially by geometric and extra-geometric
models have investigated the use of spatial prepositions,
variables. Coventry, Prat-Sala and Richards [5] found that
and their role in spatial cognition.
the comprehension of over and under was more influencedby function than above and below, while the comprehension
1.1 Psychological Literature on Spatial Language and
of above and below was better predicted by geometry than
Function over and under. In addition, effects of extra-geometric
In the experimental psychological literature it has been
shown that both geometric (e.g., the distance between two
comprehension even when the prototypical geometric
objects and their relative orientation) and extra-geometric
variables (e.g., the function of an object and its size and
appropriateness ratings of expressions such as the umbrellais over the man to describe a picture of a man holding an
Sadler's [11] spatial templates for the prepositions over,
umbrella were reduced when rain was depicted as falling on
the man even when the umbrella was depicted directly
The Regier model, even though it is able to reproduce
many of the experimental and cross-linguistic data on theuse and learning of spatial terms, has the limitations of
1.2 Neural Network Models of Spatial Language
relying only on geometrical-based processing and only
There is some computational work that has modeled the
deals with abstract objects. The network uses different
acquisition and use of spatial terms using neural networks
geometrical indices, such as the center of mass between the
two objects, their minimal distance, and the overlapping of
approach. Harris [9] used neural networks to model the
their shapes. Although the use of these geometric
polysemy of the preposition over, that is the fact that the
components does allow the system to deal with change over
term over appears to have many different senses, such as
time, no other information is extracted and used, such as
"being above", "up", "across", etc. Harris's model used
Recently, a new computational model for spatial
propagation to learn to associate the correct meaning of
language has been proposed by Regier & Carlson [13]. This
over with different sentences. All input sentences contained
does not use connectionist techniques. It is based both on
the term over to relate the position of a figure object with
attentional factors on the processing of geometrical features
respect to a ground object. After learning the correct
mapping of the meanings of over, the activity of some ofthe hidden units auto-organizes in a way that units become
sensitive to certain features of the object set used in thetraining sentences. There are units whose activation
The prototype of a hybrid NN and VR system has been
distinguishes between objects which are or are not normally
developed. The NN learns to use spatial prepositions in
in contact with a surface, and other units that are sensitive
response to input stimuli describing geometrical and
to the size and shape of the objects.
functional relationships between two objects. The NN
The model introduces the problem of polysemy and
module is integrated with a VR interface, where a user can
openness of the meaning of some spatial terms [9]. It shows
directly manipulate geometric and extra-geometric factors.
the emergence of the role of object-knowledge effects for
This system can be used as an experimental tool for spatial
spatial language using auto-organization systems, such as
language and for natural language interfacing in VR
neural networks. However, this work lacks any reference to
the role of geometrical features in the learning and use ofspatial prepositions. The encoding of input in only linguistic
2.1 Neural Network
terms does not allow any processing of geometrical
The NN architecture consists of a multi-layer perceptron.
properties between objects. The neural network model is
The input layer receives information about a visual scene
subject to the problem of symbol grounding in cognitively
depicting specific spatial configurations of objects. The
output units activate the correct spatial preposition(s)
Terry Regier [12] has proposed a computational model
describing the scene. The network has four output units,
for spatial prepositions using a method called "constrained
respectively for the prepositions over, above, under and
connectionism" [6]. The model is trained on the use of
below. The activation of each unit corresponds to the level
various spatial prepositions for static (e.g. over and above)
of agreement for the use of a specific term. After training,
and moving (e.g. through) objects, and makes explicit use
the activation must correspond to the subjective ratings
of the processing of geometrical information. The model
collected in experimental studies. The hidden layer contains
consists of a complex neural network in which the units'
five units, a number sufficient for the network to learn the
layers and connection patterns are structured according to
training data. The number of input units varies according to
neuropsychological and cognitive evidence; only a few
the explicit/implicit encoding of some of the properties of
units are based on unstructured parallel distributed
processing. An image of two objects (ground and figure) is
The training and testing task utilize the stimuli and data
input to the lower layer of the network. Then the image
from an experiment on the role of functional factors in the
goes through several levels of geometrical processing. The
rating of the spatial prepositions over/above/under/below
output units, corresponding to spatial prepositions, are
(experiment 2 in [5]). In this study, subjects used a 7-point
activated according to the geometrical position of the figure
Likert scale to rate the use of the four spatial prepositions
object with respect to the central ground. Regier [12] tested
this model for various cognitive and cross-linguistic spatial
holding/wearing an object (e.g. umbrella, visor) to protect
language phenomena. For example, the model proved
himself from another object (e.g., rain, spray). In this
suitable for reproducing the experimental data of Logan &
experiment four independent variables were manipulated:ORIENTATION of the protecting object (3 levels: an umbrella
Figure 1: Examples of experimental conditions in the second experiment of Coventry et al. [5]. The three scenes differ in the level of variable FUNCTION. In the control condition (left) there is not rain, in the non-functional condition (center) the umbrella does not protect the man from the rain, and in the functional condition (right) the umbrella is fulfilling its function of protection the man from the rain.
can be rotated at 90, 45, and 0 degrees) FUNCTIONfulfillment of protection from the rain (3 levels: yes, no,
variable. Two units encode the levels of APPROPRIATENESS,
function, e.g. umbrella or suitcase (2 levels: yes, no) and
Network B: Localist Object Encoding
OBJECT type (4 levels). This results in 72 experimental
This network does not have an explicit representation of the
scenes/conditions. An example of three scenes is presented
object appropriateness, because eight localist units are used
in Figure 1. The scenes differ in the level of the variable
to represent all objects. There are also three localist units
for ORIENTATION and three for FUNCTION. This architecture
Three network architectures are used. They only differ in
the number of input units and the way input scenes are
Network C: Feature-based Object Encoding
encoded. The five hidden units and the four output units are
In this network the objects are encoded according to their
the same in all networks (Figure 2).
geometrical and functional features. Each object isrepresented using eight feature-based units. Three unitsencode the dimension of the object in the three dimensions(x, y, z) and three encode the major shape components(hemispherical, conical, cuboid). Two units refer to thelexicalized function of the object (i.e. APPROPRIATENESS). For example, the object umbrella is encoded as x=1, y=1,z=.67,
appropriate=1, inappropriate=0. There are three localist units for ORIENTATION and three forFUNCTION. This architecture has a total of 14 input units.
A standard error backpropagation algorithm was used, witha learning rate of .01, momentum of .9 and 10000 epochs. Of the total of 72 scenes, 71 were used for each trainingepoch, and 1 for the generalization test. The training of eachnetwork type A/B/C was replicated ten times, by varying
Figure 2: Neural network architecture
the initial random weights and the stimulus randomly takenout for the generalization test. Network A: Localist experiment encoding
The subjects’ mean ratings for the use of the four
In this network, the number of input units exactly reflects
prepositions were normalized in the range 0-1 and were
the number and levels of the four experimental variables.
used as teaching input for the backpropagation training.
This architecture has a total of 12 localist input units. Weuse the term localist to indicate that for each variable only
2.2 Virtual Reality Environment
Three input units are used to encode the three levels of
manipulation of 3D objects in the scene. For example, in
ORIENTATION of the protecting object. Three localist units
the umbrella scene there are three objects that the user can
are used for the three levels of the FUNCTION independent
manipulate: the man, the protecting object (e.g. umbrella or
suitcase), and the rain. For the protecting objects, the user
each preposition that were passed back to the VR interface
can edit some of their features, such as the size and rotation.
The program starts by showing an almost full-screenwindow with eleven buttons and displays a man with his
Table 1: Average training and generalization errors for the three
right hand up. This man is rotated 60 degrees around his Y-
axis. The user can then display/hide an object and edit its
features. Once all the attributes are ready, the user can click
on the “NNAnswer” button to ask the NN module to
provide the rating for the four prepositions (Figure 3). 3.2 Analysis of Internal Representations To understand the way geometrical and extra-geometrical factors are processed by the networks, a cluster analysis of the hidden activation was performed. This informs us about the major criteria used by the network to perform the spatial language task. A greater distance between clusters indicates which variables are used first to process (i.e. separate) stimuli and experimental conditions.
For each of the three network architectures, we chose the
five out of the ten replications with the best learningperformance. The connection weights of the fifteen selectednetworks after epoch 10000 were used to calculate thehidden activation. The activation values of the five hiddenunits for each of the 72 input scenes were saved and used toperform a cluster analysis. Subsequently, we studied the
Figure 3: Interface of the VR system. The user can choose the
cluster diagrams to identify the order in which some
protecting object to display and edit its features. After the NNprocesses the scene, the ratings for the four spatial prepositions
functional and/or geometrical factors are used to separate
are shown in the bottom right corner of the interface.
clusters of experimental scenes. Although there wasvariability between the five cluster analyses of eacharchitecture, it was possible to identify some common
This VR module was developed in Java using Borland’s
clustering strategies for each condition.
Builder Java3D library. Through the Java3D API is possibleto create simple virtual reality worlds. The Java program
also controlled the communication with the NN module
With the experiment encoding architecture there are three
diagrams that share the use of common and consistentclustering criteria. In these networks, clusters are created
3 Results
ORIENTATION variable. The first divisions group inputscenes according to the degree of rotation (0, 45, 90) of the
3.1 Training and generalization
protecting object. The second consistent clustering criterion
The training task was relatively easy to learn for a
groups scenes according to the type of objects falling on the
multiplayer perceptron, mainly due to the limited set of
man (e.g. rain or spray). In the fourth diagram, the early
training data (71 training stimuli). The final error for all
clustering criteria are a mix of the FUNCTION fulfillment and
different architectures resulted in an average SSE 0.05. The
the ORIENTATION variables. The fifth diagram does not
networks were also able to generalize well to the stimulus
have an identifiable clustering criterion.
taken out from the training set. The average generalization
error for all architectures was 0.04. Table 1 reports the
In the five diagrams for the architecture with localist object
detailed average errors for each architecture. The results are
encoding, the early divisions into clusters are determined by
similar in the three conditions, with a tendency for the
the variables ORIENTATION and by that of the falling object.
feature-based object encoding network to reach lower
There is not clear and consistent prioritization of these two
The whole VR and NN system was also successfully
tested. After manipulating the properties of objects in the
VR interface, the network produced the correct rating for
The condition with feature-based encoding of objects hasfour diagrams that share the same clustering criteria. The
affect the use and comprehension of spatial terms [2].
APPROPRIATENESS of objects for the protection function.
Secondly, the clusters are then subdivided according to the
geometrical properties (e.g. through feature-based input unit
type of falling objects. Thirdly, scenes group into clusters
of network C) and its subsequent effect on the network
that have similar dimensions or shape components. Figure 4
processing strategies seem to more adequately reflect the
shows a cluster diagram for this condition. A major
phenomena observed in experimental subjects. This better
difference between this condition and the other two is that
match between the network and experimental data favors
up to the last level of clustering the appropriate and
the use of such a type of architecture for the further
inappropriate objects are always kept separate. In networks
development of a computational model of spatial language
A and B only at the level of the final clusters the two
objects are separated. Finally, one cluster out of five uses anunclear and inconsistent grouping strategy. 4 Conclusion
This hybrid NN and VR system allowed us to model the
effects of functional and geometrical factors on the
provides a prototype NLP interface for interactive VR
Further research is being conducted in order to develop a
psychologically plausible neural network model for theprocessing of spatial language. The current prototype modelshows the importance of explicitly encoding and inputtingthe extra-geometrical features of objects, as well as theirgeometrical properties. However, the use of a pre-defined
set of functional features and its distributed and explicit
encoding in the input units is not yet satisfactory. Acomputational model of spatial language and cognitionshould be able to derive, on-demand, and use the right set of
properties that are salient to the scene and its context. Thisis the direction that we are following in our on-goingresearch. References
[1] Carlson-Radvansky, L.A. & Radvansky, G.A. (1996). Theinfluence of functional relations on spatial term selection. Psychological Science, 7(1), 56-60. [2] Coventry, K.R. (in submission). Spatial prepositions and theinstantiation of object knowledge: the case of ‘over’, ‘under’,
Figure 4: Cluster analysis diagram of the hidden units’ activation
of a network of condition C (feature-based encoding). Input
[3] Coventry, K.R. (1998). Spatial prepositions, functional
relations and lexical specification. In P. Olivier and K. Gapp
approriateness/inappropriateness), and subsequently according to
(Eds.), The Representation and Processing of Spatial Expressions,
the type of falling objects and the similarity of the shape
pp247-262. Lawrence Erlbaum Associates.
components. Pure geometrical factors such as the orientation of
[5] Coventry. K.R., Carmichael, R. & Garrod, S.C. (1994). Spatial
the protecting object are ignored in the early stages of processing.
prepositions, functional relations and task requirements. Journal ofSemantics, 11, 289-309.
Overall, the results of hidden activation clustering show
[4] Coventry, K.R., Prat-Sala, M. & Richards, L. (2001). Theinterplay between geometry and function in the comprehension of
that with architectures using localist encodings (networks A
‘over’, ‘under’, ‘above’ and ‘below’. Journal of Memory and
and B), geometrical factors such as the orientation of the
protecting object prevail. When an explicit encoding of
[6] Feldman J., Fanty M. & Goddard N. (1988). Computing with
extra-geometrical factors is used, as with architecture C, the
structured neural networks. IEEE Computer, 21, 91-104.
stimuli tend to primarily group according to variables
[7] Garrod, S.C. & Sanford, A.J. (1989). Discourse models as
related to the function of objects. Most of these extra-
interfaces between language and the spatial world. Journal of
geometrical variables, such as the object’s lexical functional
appropriateness and its size, have been proven to greatly
[8] Harnad S. (1990). The Symbol Grounding Problem. Physica
[12] Regier, T. (1996). The human semantic potential: Spatiallanguage and constrained connectionism. Cambridge, MA: MIT
[9] Harris C. (1990). Connectionism and cognitive linguistics. Connection Science, 2(l), 7-33.
[13] Regier, T. & Carlson, L.A. (in press). Grounding spatial
[10] Herskovits, A. (1986). Language and spatial cognition.
investigation. Journal of Experimental Psychology: General.
[11] Logan, G.D. & Sadler, D.D. (1996). A computational analysis
[14] Talmy, L. (1983). How language structures space. In H. Pick
of the apprehension of spatial relations. In P. Bloom, M. A.
& L. Acredolo (Eds.), Spatial orientation: Theory, research and
Peterson, L. Nadel, & M. Garrett (Eds.), Language and Space, pp
application (pp. 225-282). New York: Plenum.
TYRX® Brand AIGIS ® Rx ST Antibacterial Soft Tissue Repair Device Minocycline and Rifampin eluting polypropylene mesh sheet Manufactured and distributed by: TYRX, Inc. STERILE: Contents sterile unless package has been opened or damaged. Single use Only. Do not Resterilize. CAUTION: Read instructions prior to use. Rx Only PRODUCT DESCRIPTION AIGIS ® Rx ST is a dual com
(Actos cuja publicação é uma condição da sua aplicabilidade) REGULAMENTO (CE) N.o 1662/2006 DA COMISSÃO de 6 de Novembro de 2006 que altera o Regulamento (CE) n.o 853/2004 do Parlamento Europeu e do Conselho, que estabelece regras específicas de higiene aplicáveis aos géneros alimentícios de origem animal (Texto relevante para efeitos do EEE) consumo humano. O óleo de p





 suitcase), and the rain. For the protecting objects, the user
each preposition that were passed back to the VR interface
can edit some of their features, such as the size and rotation.
suitcase), and the rain. For the protecting objects, the user
each preposition that were passed back to the VR interface
can edit some of their features, such as the size and rotation.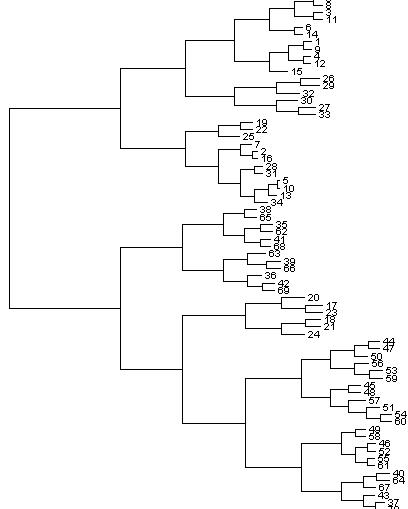 affect the use and comprehension of spatial terms [2].
affect the use and comprehension of spatial terms [2].